Quick Start Guide to Big Data Analytics for Large Enterprises

A great deal of today’s biggest corporations – regardless of which market they target – want to leverage the data they have to create new services. As often stated, data is the oil of this century: an immense, untapped valuable asset. As big as these corporations have grown, however, so has what I term their "inner immune system."
As long as business runs smoothly, we do not notice the company's immune system. The immune system is like a guardian, responsible for protecting the company from harmful influences. As long as innovation (an intruder after all) has not proven to be good for the firm, it will be attacked. But building something new and exploring fresh paths sometimes means leaving the old known ones, that is, stepping into uncertain and potentially dangerous areas. High-risk innovations are therefore usually the prerogative of small businesses such as start-ups.
In the past, I founded a start-up, worked at Volkswagen for several years as researcher and IT architect for Mobile Online Services, and now work for a mid-sized company called Sevenval Technologies as head of a team devising a big data analytics dashboard for application performance monitoring. I've therefore been able to look at this problem from different angles. In this post, I’d like to share best practices on how big corporations can overcome this dilemma and act like a start-up to pave the way for valuable data analytics.
(1) Do not re-invent the wheel
While pursuing my Ph.D. I learned that there are no new problems. Researchers seek to find new solutions to well-understood problems. Especially in computer science, well-understood problems are usually solved in an innovative way when technology improves. When doing research it is essential to understand your problem in the first place, and to compare it to one that other researchers have already investigated. I plan in the future to write a more detailed post about all use cases which I had contact with. In the meantime, the following chart should help you to roughly identify your problem. It shows you four categories, to which most of the use cases which I have found in literature can be allocated: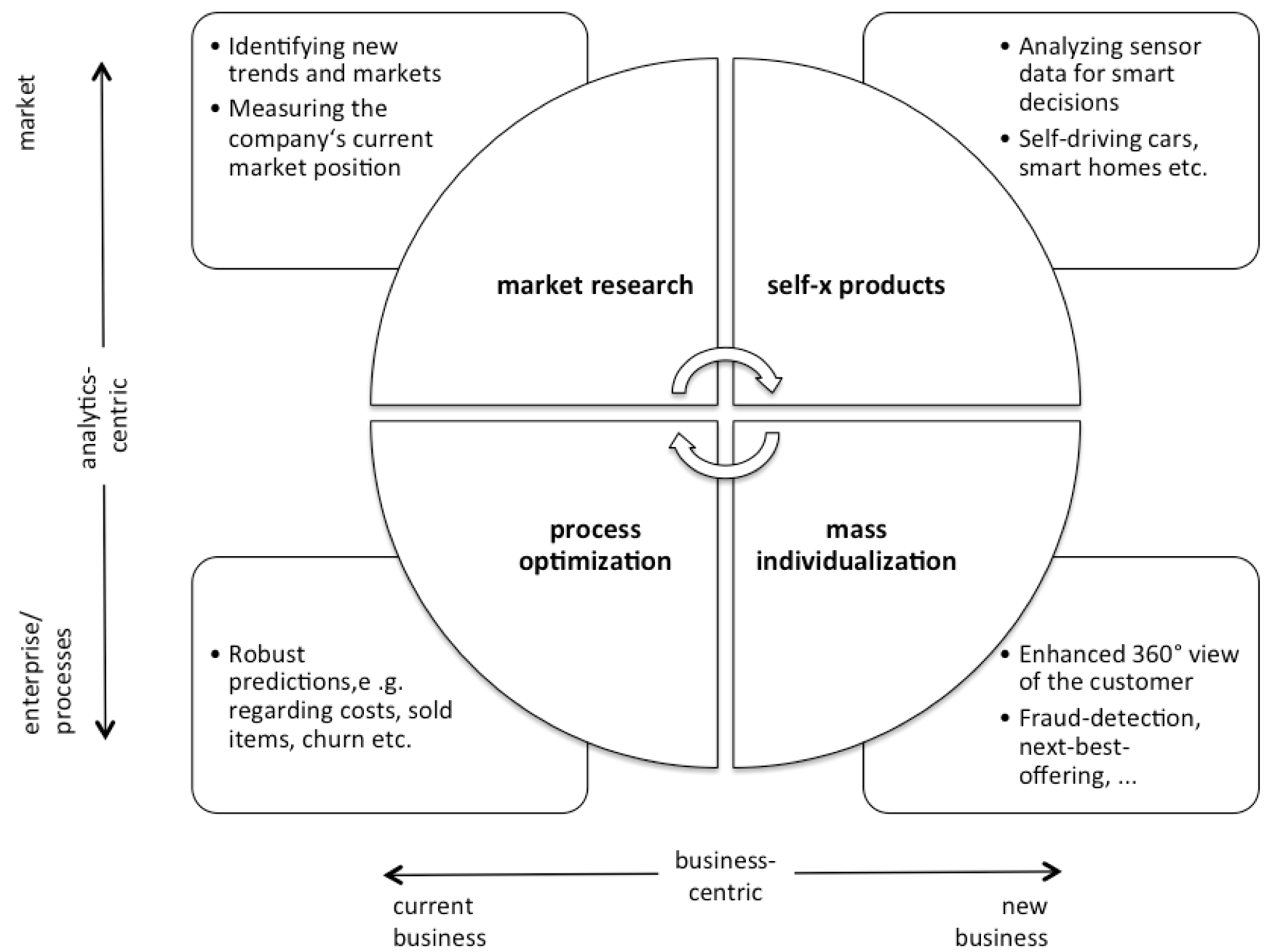
(2) Un-silo your data
The vast majority of people, when they hear the words big data and data mining, think of smart guys developing crazy algorithms to bring Terminator’s Skynet to life. To be honest, data scientists spend at least 80 percent of their time on data cleansing. They implement fancy algorithms only 20 percent of the time. That is to say, big corporations, as well as any other company, have to focus on data cleansing in the first place before devising sophisticated data mining algorithms. In my experience at Volkswagen, for instance, we set up a car fleet for sampling floating car data, or data generated in a car and sent to the back end, on a nearby motorway in the morning hours. We wanted to utilize the data to develop a data mining algorithm to detect traffic jams by clustering car speeds for predictive analytics. We recorded one week of data. It took four days of data cleansing, i.e., smoothing GPS trajectories, detecting data sets with inaccurate data, and correcting timestamps, before we were able to implement our idea of dynamic Kalman filtering in just a single day.The most efficient way to cleanse data is to identify the useful subsets. To identify them, you have to know your data. Therefore, you need a domain expert for every silo which contributes to your data. For example, car manufacturers like Volkswagen design cars. According to Conway's law, they are constrained in producing designs which are copies of their communication structures. Car manufacturers have departments for all components contributing to the car setup, for instance, the lights, the brakes, propulsion and so on. Accordingly, when I set up the car fleet, I had to talk to all departments whose components I used such as the connectivity, localization, and mapping unit. Since my data points (the vehicle's speed associated with the original and mapped GPS position) passed through these components and was modified by each of them, I had to understand the entire modification chain. I achieved this by conferring with each of the domain experts and so un-siloed the data.
The next step is connecting data sets. Sometimes you want to intersect datasets such as a user database with data describing user behavior. For example, enterprises in the telecommunication sector link their user database to customer support tickets and retention rates on their website to predict churn, or the loss of customers to some other company. They use a user ID to identify data sets stemming from the same user. Regarding the car fleet described above, I could not simply use a user ID. I had to join data sets from different cars in order to cluster their positions. That is why I had to take the cars' locations and timestamps to merge their respective data sets. Both of these can suffer from measuring inaccuracies. For example, the GPS signal in space provides a worst-case pseudo range accuracy of 7.8 meters at a 95% confidence level. Real-world data, however, usually suffers from an inaccuracy of up to 20 meters. The timestamp from the GPS signal is bound to the same error. We had plenty of cars with inaccurate timestamps due to GPS signals disrupted by atmospheric effects and sky blockage. In summary, connecting data sets is a very tricky process which directly affects your overall data quality. Do it with great care.
(3) Move into the cloud
Very often I have seen how a big data analytics project is transformed into a big data infrastructure project when the IT department comes into play. Data privacy issues and the fear of potential misuse of data stored in the cloud compels big companies to store and analyze the data within their IT infrastructure. In particular, if you process sensitive personal data, such as personally identifiable information, you must satisfy specific conditions defined by the company itself or by the government. Google, for instance, had to blur out faces and facades on German street view data, since in Germany it is forbidden to photograph people or their property without their permission and upload this information to the public domain. Similarly, I had to blur out all car signs in the video data that we recorded with the car fleet setup, since this data can be used to personally identify people. If you are concerned by potential data misuse and want to respect data privacy (which you really should!), pseudonomize your data before uploading. You can, for example, divide your data sets into sub sets. Regarding the car fleet we split up the GPS trajectories, which are undoubtedly personally identifiable information, into sub-trajectories. The initial starting point, i.e., the driver’s home, was thereby hidden. Additionally, we filtered out all data which was not generated on the motorway itself. This may lead to restrictions regarding your analytics, but most importantly your data is secure. The security of the data should be paramount.Big corporations usually align and optimize their IT according to their business cases. Car manufacturers, for example, set up their infrastructure according to their needs producing cars and managing customer support. Their networks are inherently not optimized for high I/O, or Input/Output, operations that transfer data to or from a computer and to or from a peripheral device, and number crunching which you need for analyzing big data sets. Additionally, for increased flexibility they virtualize their networks which conceptually conflicts with the idea of MapReduce (a method to process vast sums of data in parallel) processing the data where it is. To install a MapReduce framework such as Hadoop in a virtualized environment is one of the worst mistakes you can make.
Summary
We can conclude that it is all about identifying the most important points and increasing flexibility in large enterprises. Prioritizing is essential to keep up momentum and avoid conflicts due to the company’s inner immune system. Big enterprises are usually restricted in terms of their flexibility, however, this is essential to start something new. If you can manage to keep up prioritizing and increase flexibility as a big company, you can be as innovative as a start-up.I hope you enjoyed my first post.