Cheating My Wife…or How I Trained a Chatbot to be Me

First things first: I’m still a happily married man! In this post, however, we’ll look at how Deep Learning — especially Recurrent Neural Networks — can be used to actually teach a Chatbot. By using my past WhatsApp conversations with my wife, the Chatbot learns to respond to messages the way I would. So, we’ll try to pass the Turing Test to see if my wife detects if it is me or a machine.

Taken from https://medium.com/@creativeai/creativeai-9d4b2346faf3
Our World is Changing (faster than you might think)
Currently, the automotive industry is crazy about Chatbots. There are several initiatives going on at Volkswagen, where we try to leverage their potential for customer support, on-board assistance, or internal process optimization. Apple’s Siri, Microsoft’s Cortana, Google Assistant, and Amazon’s Alexa have laid the foundations for creating great automotive applications based on them. All of them have built-in auditory interfaces by which the bot is able to communicate with you by audio messages. Understanding spoken words and converting them to textual messages, and vice versa, is only one part of a good Chatbot though. The most important part—what I call the heart of the Chatbot—is its ability to find the right textual answers to textual input. This is where Deep Learning recently stepped in and delivered great results in creating realistic and effective Chatbot interactions. This is why Facebook (FB) has been massively investing in FB Messenger bots, which enable small and mid-sized businesses to set up support bots automating their FAQ sections.
At the AI Summit of Copenhagen’s Tech Festival last year, Samim Winiger gave a great presentation about creative AI and how bots will take over some of our jobs but also help us to create new ones, for example, by being more creative.
The following is taken from his website and gives a concrete example regarding assisted writing:
“Writing is an ancient art form. From Papyrus to MS-Word, the tools we use to write have defined how and what we write. Today, assisted writing tools are using machine learning techniques to understand, manipulate and generate human language. The implications are profound.” Imagine, for example, that future scientific romans will be created by assisted writing, as described in Sami’s blog post and shown in the following animated GIF.

Have a look at these astonishing examples which I took from his website, where bots create 18 quintillion (1018) game universes in three years instead of one designed by an human in this time period or bots create nuances of objects by using autoencoder networks that have never existed before (for example faces).
Samim also writes, “We live in times, where science-fiction authors are struggling to keep up with reality. In recent years, there has been an explosion of research and experiments that deal with creativity and A.I. Almost every week, there is a new bot that paints, writes stories, composes music, designs objects, or builds houses.”
So, to fully understand current state of the art implementations of the “heart” of Chatbots based on Deep Learning, I thought it would be funny to teach such a bot on WhatsApp, using conversations with my wife to see if she would detect whether it was me or not. If she didn’t detect it, I would pass the Turing Test.
The Turing Test
The Turing Test, which Alan Turing developed in 1950, is a test of a machine’s ability to exhibit intelligent behavior. Intelligent behavior means that it equals human behavior or that you can at least not distinguish if it’s a machine or not. Turing stated that a human evaluator would judge natural language conversations between a human and a machine that was implemented to generate human-like replies. The conversations would be limited to a text-only channel, such as a chat. So, the result would not depend on the machine’s restrictions to render words as speech or to understand spoken words. If the evaluator is not able to reliably say whether it’s a machine or a human, answering the messages, the machine is said to have passed the test. The test does not check the ability to give correct replies to questions, only how similar answers are to those a human would give. So, if my wife doesn’t recognize that it’s not me when answering her WhatsApp messages, my bot would pass this test.
If you want to get an entertaining introduction to the Turing Test, watch the movie “Ex Machina”.
Understanding the Challenges
From a very high-level perspective, the task of a Chatbot is to find the best-matching reply for each and every received message. This “best-matching” reply should either:
- Give a meaningful answer to the sender’s question,
- Give the sender relevant information,
- Ask follow-up questions, or
- Continue the conversation in a realistic way.
This means that the Chatbot must be able to understand the sender’s intention and give a good reply (either a direct reply or a follow-up question). In addition to this, the reply has to be compliant to all lexical and grammatical rules of the corresponding language. That’s a big challenge. Now we definitely have enough on our plate.
At least by looking closer at the last requirement of answering messages in a correct lexical and grammatical way, you understand why Deep Learning entered this domain and delivers great solutions for this complex, non-linear problem. Neural networks are still the leader of the pack in this section. They are able to create powerful implementations of complex non-linear functions as you find them in image processing, speech-to-text, or text-to-speech processing.
Mastering the Non-Linearity: The Deep Learning Approach
Let’s do the theoretical things now. It’s not very complicated, but you can also leave this section out and proceed with the next one, where we’ll get our hands dirty on practically implementing a Chatbot.
All Chatbots are based on the Deep Learning leverage sequence to sequence (Seq2Seq) model. Ily Sutskever, Oriol Vinyals, and Quoc Le laid the foundations by publishing a paper with the title “Sequence to Sequence Learning with Neural Networks” in 2014. This paper showed great results in machine translations. In the meantime, however, Seq2Seq models have conquered several other Natural Language Processing related fields. And the strategy is always the same: Map the input sequence to a fixed-sized vector using one Recurrent Neural Network, and then map the vector to the target sequence with another Recurrent Neural Network. But, what are Natural Language Processing and Recurrent Neural Networks, and what are they good for?
Natural Language Processing (NLP) is all about creating systems that process or “understand” language in order to perform certain tasks. These tasks could include:
- Question answering (what Siri, Alexa, and Cortana do)
- Sentiment analysis (determining whether a sentence has a positive or negative connotation)
- Image to text mappings (generating a caption for an input image)
- Machine translation (translating a paragraph of text to another language)
- Speech recognition and part of speech tagging
- Name entity recognition and so on.
The traditional approach to NLP involved a lot of domain knowledge of linguistics itself. Understanding terms such as phonemes and morphemes were pretty standard as there are whole linguistic classes dedicated to their study. RNNs are the go-to for most NLP tasks today. The big advantage of the RNN is that it is able to effectively use data from previous time steps. This is what a small piece of an RNN looks like.
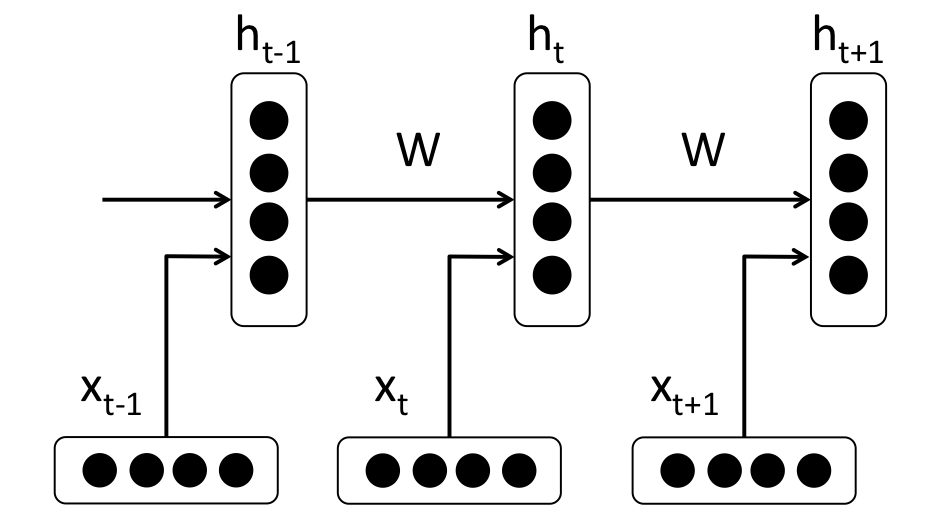
So, at the bottom we have our word vectors (xt, xt-1, xt+1). Each of the vectors has a hidden state vector at the same time step (ht, ht-1, ht+1). W is the word vector that shows the occurrences of words in the text and their relationship in a matrix. Let’s call this next one entity.
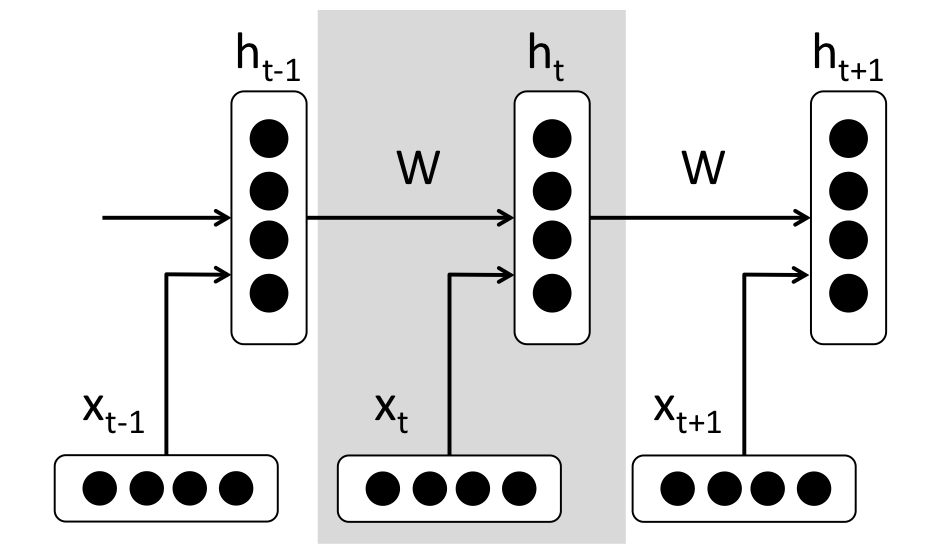
The hidden state in each entity of the RNN is a function of both the word vector and the hidden state vector at the previous time step.
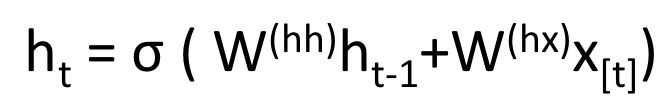
If you take a close look at the superscripts, you’ll see that there’s a weight matrix Whx, which we’re going to multiply with our input, and there’s a recurrent weight matrix, Whh, which is multiplied with the hidden state vector at the previous time step. Keep in mind that these recurrent weight matrices are the same across all time steps.
This is the key point of RNNs.
Thinking about this carefully, it’s very different from a traditional 2 layer NN. In that case, we normally have a distinct W matrix for each layer (W1 and W2). Here, the recurrent weight matrix is the same through the network.
To get the output (ŷ) of a particular module, this will be h times WS, which is another weight matrix.
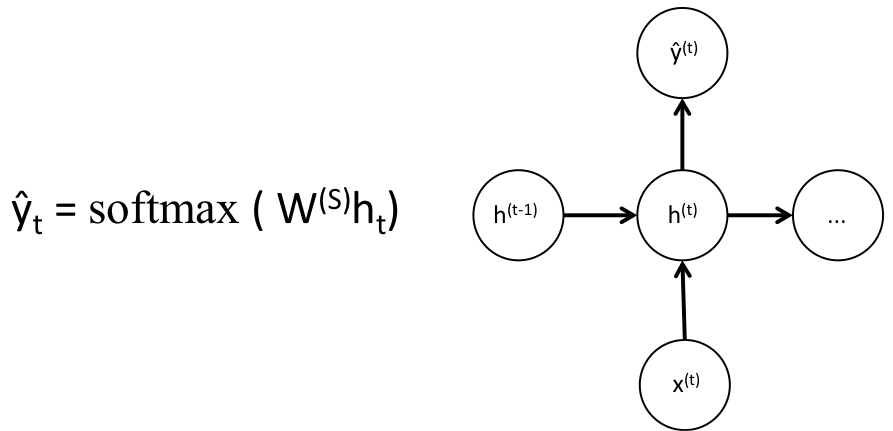
Let’s take a step back now and understand what the advantages of an RNN are. The most distinct difference from a traditional neural network is that an RNN takes in a sequence of inputs (words in our case). You can contrast this to a typical convolutional neural network where you’d have just a singular image as input. With an RNN, however, the input can be anywhere from a short sentence to a five paragraph essay. Additionally, the order of inputs in this sequence can largely affect how the weight matrices and hidden state vectors change during training. The hidden states, after training, will hopefully capture the information from the past (the previous time steps).
It consists basically of two main components: an encoder and a decoder RNN. From a bird’s eye view, the job of the encoder RNN is to transform the input text into a fixed representation. The job of the decoder is to unfold this representation to a text of variable length, which should be the best response.
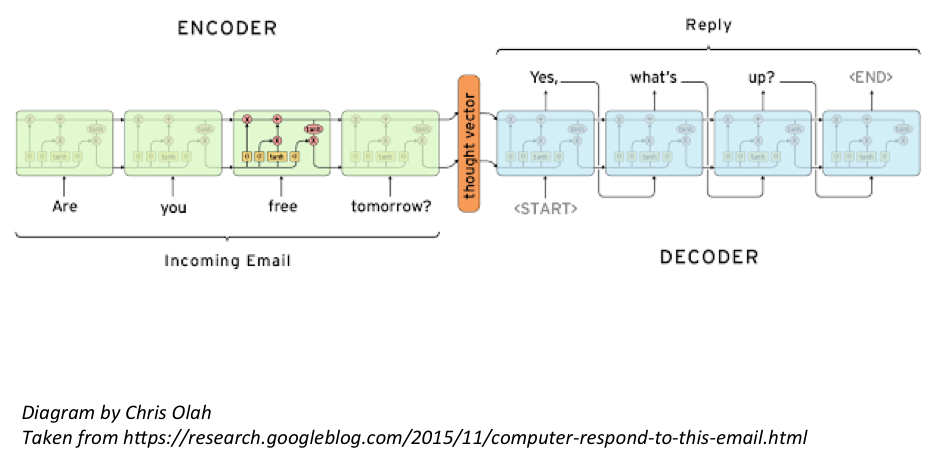
Let’s dig into RNNs in more detail. As already explained, an RNN consists of various hidden state vectors. Each of the hidden state vectors stand for information from the previous time step. The hidden state vector at the 4th time step, for example, will be a function of the first four words. Based on this logic, the encoder’s final hidden state vector should be a quite good representation of the entire input text.
The decoder RNN is responsible for processing the encoder’s final hidden state. It utilizes it to predict the words of the output response. So, the decoder’s first cell takes in the vector representation v and computes which word in its vocabulary is the most likely one for the output response. From a mathematical perspective, this means that we compute the probabilities for each word in the vocabulary and choose the one with the highest probability.
The second cell will be a function of the vector representation v and the output of the first cell. Our goal is to estimate the following conditional probability to form some kind of long short-term memory on words:
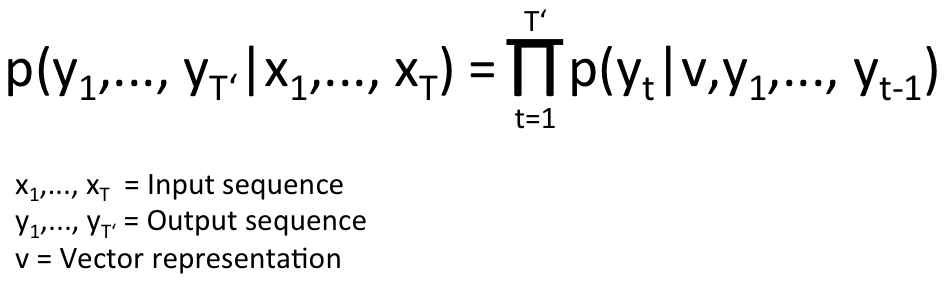
Let’s have a closer look at this complex-looking equation. The left side of the equation simply says that the output depends on the given input sequence. The right side contains the term p(yt|v, y1, …, yt-1) , which is a vector of probabilities of all the words depending on the vector representation and the outputs of the previous time steps. The Pi notation is simply the multiplication. So, the right side can be written like this p(y1|v) * p(y2|v, y1) * p(y3|v, y1, y2) etc. We’ll look at a concrete example now: We take the input text of the first illustration: “Are you free tomorrow?”. Most common answers to this question should be “Yes”, “No” and so on. After training our network, the probability p(y1|v) will be a distribution which looks as follows:

The next probability which we have to compute is p(y2|v, y1). It is a function returning the most likely word based on the previous most likely word and all available words. The final result of the Pi operation will return the most likely sequence of words. This will be our final reply.
The biggest advantage of sequence-to-sequence models is their flexibility. Machine learning methods (such as linear regression and support vector machines) or cutting-edge methods such as convolutional neural networks need a fixed sized input and produce a fixed sized output. This is valid for all of them. So, the lengths of your inputs most be known beforehand. This is a crucial restriction to tasks such as machine translation, speech recognition, or question answering. Nevertheless, these are exactly the challenges where we don’t know the size of the input and output phrase. Sequence-to-sequence models give us the exact flexibility we need for such cases.
My Dataset: Don’t Tell My Wife
The most important thing for any machine learning problem is the underlying data set. This is needed for training and evaluation. For sequence-to-sequence models we usually need a large number of conversation logs. This is important to enable the encoder-decoder-network to link the inputs with the most likely outputs.
While it is most common today to train Chatbots to answer company-related information (or to provide some sort of service), I was interested in a more complicated application. I wanted to see whether I could use my WhatsApp logs from my conversations with my wife to train a sequence-to-sequence model to respond to messages the way I would.
Let’s get started now. First, I downloaded all the WhatsApp messages that I had with my wife over the last four years, resulting in approximately 5,000 conversations. A big part of machine learning is data cleansing, meaning data set pre-processing. I usually love to share datasets, but for this specific one, I keep it private to stay married :-).
It took me about 20 hours to pre-process the data in a way that I could feed it into the Tensorflow example code: https://github.com/tensorflow/nmt
I just had to replace the data files. So, I took the example where English sentences were translated into Vietnamese ones. I replaced the training files with my data set. My texts with the inputs were translated into my wife’s answers.
| Input | Output | Current loss | At iteration |
|---|---|---|---|
| Wie geht’s? | 2.81234532 | 1,200 | |
| Wie geht’s? | [ ‘:-)’ ] | 2.13454871 | 7,800 |
| Wie geht’s? | [ ‘:-)’, ‘Na’, ‘Ganz gut’ ] | 1.45678988 | 11,150 |
What is really great with Tensorflow is having the chance to look at how the responses change during the training process of the network. At distinct time steps, I tested the trained network on an input string and outputted all of the answers. You can see that the answers are initially blank, since the network outputs padding tokens. This is quite normal since padding tokens occur much more often in the whole dataset than normal words. Then, you can see that the network start to output smileys for every single input string which is given. This makes sense since smileys are nowadays so often used that it is kind of an acceptable reply. Slowly, you start to see more complete replies in German.
So finally: Did I Pass the Turing Test?
It’s probably difficult to judge whether or not the bot actually talks like me, but my wife always noticed that it wasn’t me answering her on WhatsApp when I tried to use my bot to get an answer to her input. So, I didn’t pass the Turing Test. The quality was far too low—probably due to the low amount of training data that I had. I guess you will need approximately 100,000 to 150,000 conversations to achieve acceptable results.
Pretty much, the answers were so bad that it helps me sleep better at night, since Skynet is definitely not happening any time soon.




