Hacking your Organization: Seeding a Micro Service Architecture

Micro services are currently a very hot topic in the software development community. Many articles, blogs, conferences, and tweets have addressed this topic. Micro services, however, are quickly moving towards the peak of inflated expectations on the Gartner Hype cycle. Frankly speaking, the micro service bubble is about to pop. This is driven by many skeptics in the software community who say micro services are nothing new – just a fancy repackaging of the “good old” service-oriented architecture (SOA). In spite of both the hype and the skepticism, however, the micro services architecture pattern can have significant benefits – especially when it comes to enabling the agile development and delivery of complex enterprise applications.
Conway’s law states that the structure of the software architecture is always a reflection of the organizational structure. Accordingly, you can use the micro service pattern to hack the company, since Conway’s law works in both directions. By implementing a micro service architecture you can change the nature of how your company works. I learned this first-hand while refactoring our fleet management solution ConnectFleet at Volkswagen commercial vehicles. Though it was a trying process, we are now able to quickly develop new services in distributed teams.
Introduction to micro services
The rise of micro services has been a remarkable advancement in application development and deployment. Micro services is a new approach to software development in which, an application is developed, or refactored, into separate pieces that “communicate” with each other in a well-defined way like application programming interfaces (APIs). Each micro service is a self-contained package with its own business logic and data store. So, having many micro services entails having many separate data stores, each of which can be updated independently from the others. This is important to note, since this comes with benefits but also a cost such as a higher complexity and maybe inconsistency in terms of communication.
Refactoring to a micro service-based approach enables faster development and eases the management of complex software projects. This also means that you need fewer software developers to implement more new features. So, you can innovate more quickly, which is good. Changes can be made and deployed faster and easier. An application designed as a collection of micro services is easier to scale by distributing it to multiple servers. Thereby you can easily handle demand spikes and reduce downtime caused by hardware or software problems.
As already mentioned in the introduction: By implementing a micro service architecture you can change the nature of how your company works. Agile software development techniques, moving applications to the cloud, DevOps culture, continuous integration and continuous deployment (CI/CD), and the use of containers will naturally become features of your company when you bring a micro service architecture to life.
Be fast: Centralize and start with the monolith
Let’s imagine that you were starting to build a brand new fleet management application (like ConnectedVAN). After some preliminary meetings and specifying requirements, you’d set up a new project based on a platform such as Rails, Spring Boot or Play - either manually or by using a generator.
This new application would have a modular architecture as in the following picture:
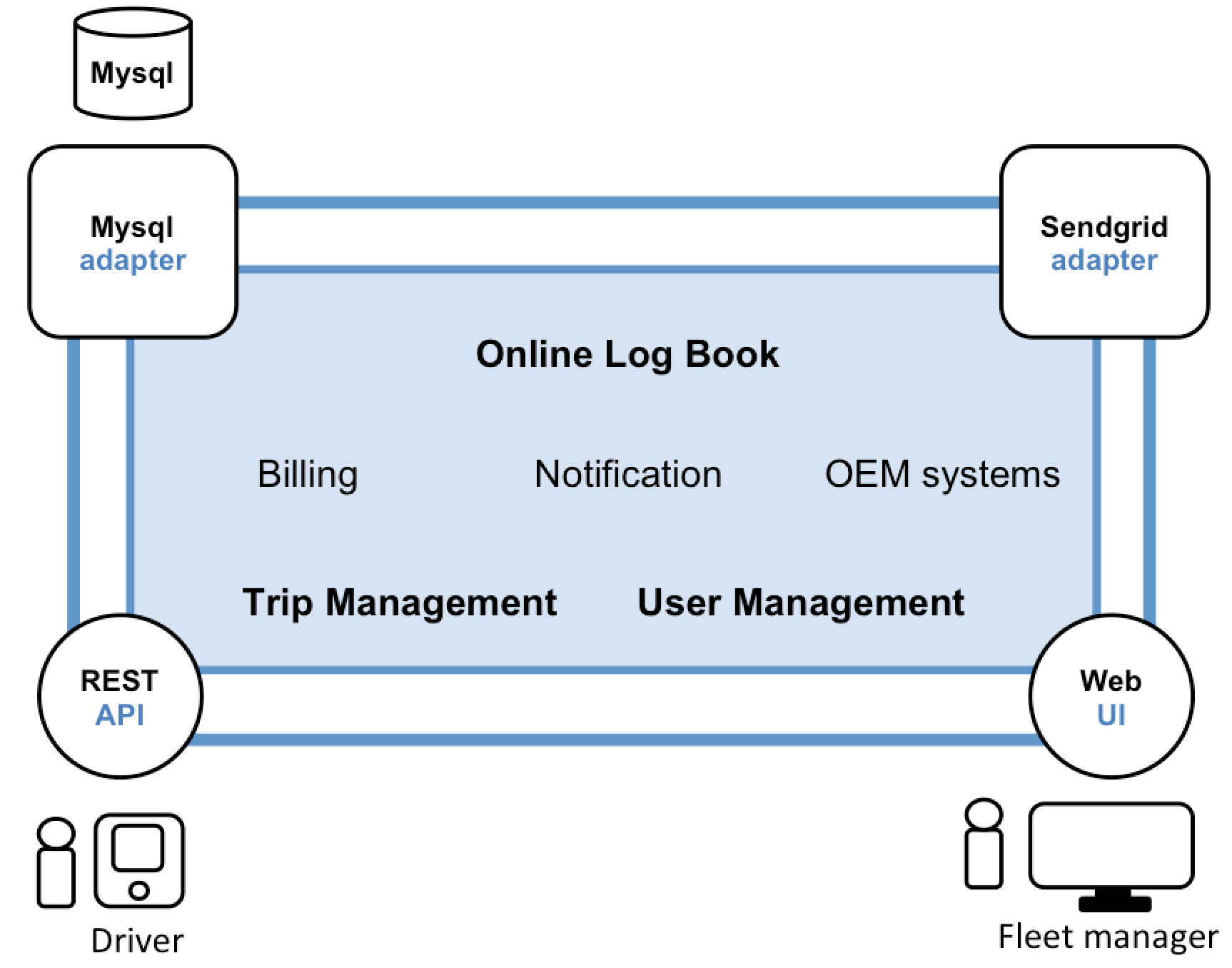
The application’s core is the business logic box, which consists of modules that implement services, domain objects, and events. For a fleet management solution the business logic is comprised of the trip and user management components which are used to offer an online log book for the fleet manager, as well as services for billing, notification and connecting car manufacturer specific systems like importing car data. Expanding the core are adapters that interface with the external world. Examples of adapters include database access and messaging components that create and consume messages, and web components that either expose APIs or implement a user interface (UI).
In spite of having a logically modular architecture, the application is shipped and deployed as a monolith. The actual format depends on the application’s programming language and framework. The majority of Java applications, for example, are shipped as so-called WAR files and deployed on application servers such as Tomcat, JBoss, or Jetty. Other Java applications are packaged as self-contained executable JARs. Similarly, Rails and Node.js applications are packaged as a directory hierarchy. Such applications are very easy to write and therefore extremely common. Furthermore, the development process of such applications is well-supported by many standard integrated development environments (short IDEs). These kinds of applications are simple to test. You can implement end-to-end integration testing by simply launching the application and testing the UI with a testing package such as Selenium. Monolithic applications are also easy to deploy. You just have to copy the packaged application to a server. You can also scale the application by running multiple copies behind a load balancer. In the early stages of the project this approach works well, allowing you to work quickly and focus on the business logic.
Beware of losing speed
Unfortunately, this simple approach has limitations when you grow (in terms of complexity and size of your application). Successful applications usually start growing over time and might become huge. With each sprint, your development teams add many lines of code for new user stories. After a few years, your small, simple application will have grown into a monolithic monster. To give an extreme example: the London-based start up Viagogo (where I worked as intern during my studies) wrote a tool to send sport and event tickets to buyers. For this, they had to analyze time zones to guarantee the customer that the last minute tickets they bought would arrive in time. We analyzed the core component for predicting these arrival times and it was thousands of lines of code. It took the concerted effort of a large number of developers over many years to create such a monster and in the end nobody wanted to dig into and rewrite this code due to its complexity and business-relevance. My takeaway: Once your application has become a large, complex monolith, your development organization is probably in a world of pain, which means it won’t be easy to re-write and grow such an application.
So, any attempts at agile development and delivery will fail. One big hurdle is that the application’s complexity is too high. It’s simply too large and complicated for any single developer to fully understand. As a result, fixing bugs and correctly adding new features becomes difficult and time consuming. Additionally, this leads to a downward spiral. If the codebase is difficult to understand, then changes might not be made correctly. You will end up with a monster of code, a dragon that your developers won’t be able to tame and control. Your development speed will slow to a crawl, your innovation speed will decrease step by step until you have noticed that you are trapped.
This may sound strange, but usually the larger an application is, the longer its start-up time. At Viagogo, for example, some developers complained about start-up times as long as 12 minutes. I’ve also heard anecdotes of applications taking as long as an hour to start up. So, if your developers have to restart the application server and suffer from such long start time times, then their valuable time will be wasted. This is another pain point that will decrease your innovation speed.
The next point that negatively affects your innovation speed is that large, complex monoliths are hard to deploy continuously. Nowadays, the state of the art for modern software as a service (SaaS) applications is that code changes are pushed to production several times per day. This is nearly impossible to achieve with a complex, monolithic application. The reason is that the whole application would have to be re-deployed every time. The long start up time is an obstacle. Due to the application’s complexity, it’s also quite hard to predict what the impact of a code change will be and how to test it thoroughly.
Scaling monoliths can also be quite challenging, since different parts of the application might have contradictory resource requirements. On my website Foodplaner.de, for example, there is one module which implements CPU-intensive image processing logic. This is usually deployed best on Amazon EC2 Compute Optimized server instances. But another module of Foodplaner.de, the food search, is based on the in-memory graph database Neo4J, which should be deployed on Amazon’s EC2 memory-optimized instances. So, when I deploy both parts of the application together, I have to compromise on the hardware choice.
Reliability can also be a big issue. Since all modules run in the same process, a bug in any module (a memory leak for example) can potentially bring down the whole application.
Last but not least, monoliths are hard to refactor to keep up-to-date with technical advancements. Leveraging new programming languages or frameworks requires rewriting the entire application. Let’s imagine, for example, you have 1 million lines of code written in PHP Symfony. If you want to bring this to Node.JS, it would be extremely resource intensive in terms of both time and cost. This usually means that monoliths are not refactored and cannot leverage new technologies. You are stuck with whatever technological choices you (or someone else) made at the project’s start.
To sum up: when a successful and business-critical application is developed as a monolith, the problem that only a few developers are able to understand this application can arise. Often these are the developers who are with you since the start of the project. If you bear with this monolith, you may be stuck with the initially chosen technology stack, which becomes less and less productive as it ages. This can make it challenging to hire new talented developers. Furthermore, it can become difficult to scale the application and operate it. As a result, agile development and continuous delivery of the application is impossible. So what can you do about it? Let’s have a look in the next section how we overcame this problem at ConnectedVAN.
Micro services – decentralize to regain speed
Today’s most innovative technology companies, such as Amazon, eBay and Netflix, have overcome this problem by implementing what is now known as the “micro services architecture design pattern.” Instead of building a single monstrous, monolithic application, the idea is to divide an application into a group of light-weight, interconnected services. You should start with a fully integrated solution - called a developer image. A colleague of mine explained it to me in this way: “Don’t cut your elephant in pieces, start with a small elephant.” In this section I explain the concept of a developer image in detail.
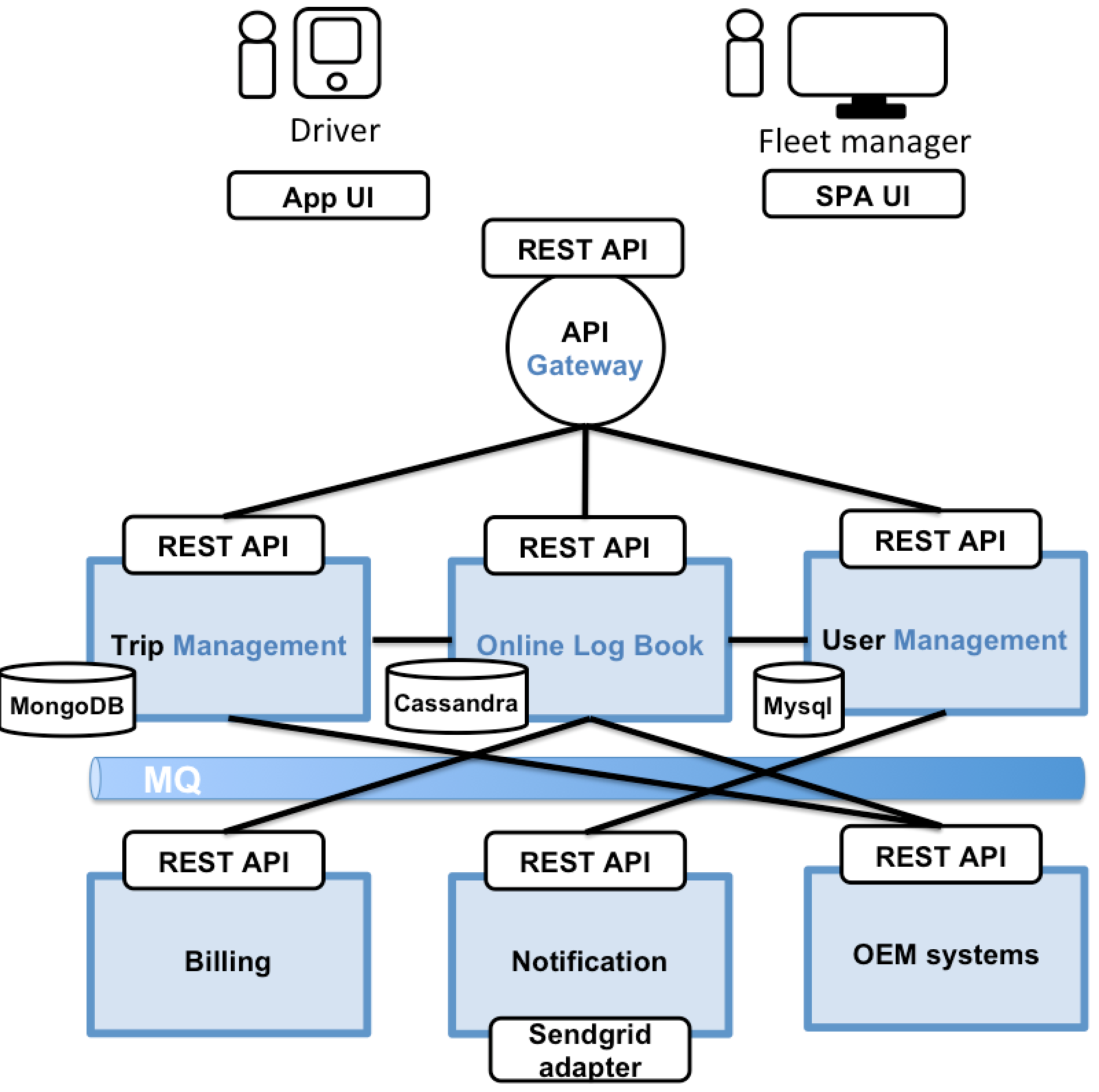
A micro service is usually a mini-application with its own architecture implementing business logic as well as various adapters. Some of them expose an API, which is consumed by other micro services. Other micro services implement a billing service, which is connected to Paypal. Each instance can either be a traditional virtual machine or - as nowadays commonly used - a Docker container.
Every function of the application can now be implemented as a micro service. This also eases the deployment of various functions. All backend services expose a REST-based API and other services consume these APIs. REST-based APIs are based on the Representational state transfer design pattern (REST). REST is a way of providing interoperability between computer systems on the Internet. REST-compliant web services allow requesting systems to access and manipulate textual representations of Web resources using a uniform and predefined set of stateless operations.
With micro services, you achieve a loosely coupled system. The user management, for example, utilizes the notification system to inform new drivers about their successful registration or send notifications to the fleet manager about their drivers' new trips. Services might also use asynchronous, message-based communication. Inter-service communication (where a sender’s message is consumed by more than one recipient) should be based on message queues to make the communication as efficient as possible. Direct, synchronous communication is handled through REST-endpoints.
Some REST APIs are also exposed to the web UI or mobile apps. This is handled through an API gateway to avoid direct communication with the backend services. The API gateway is in charge of load balancing, access control, caching, API metering and monitoring. If you use the Netflix stack, for example, you would select the open-source tool Zuul for this task.
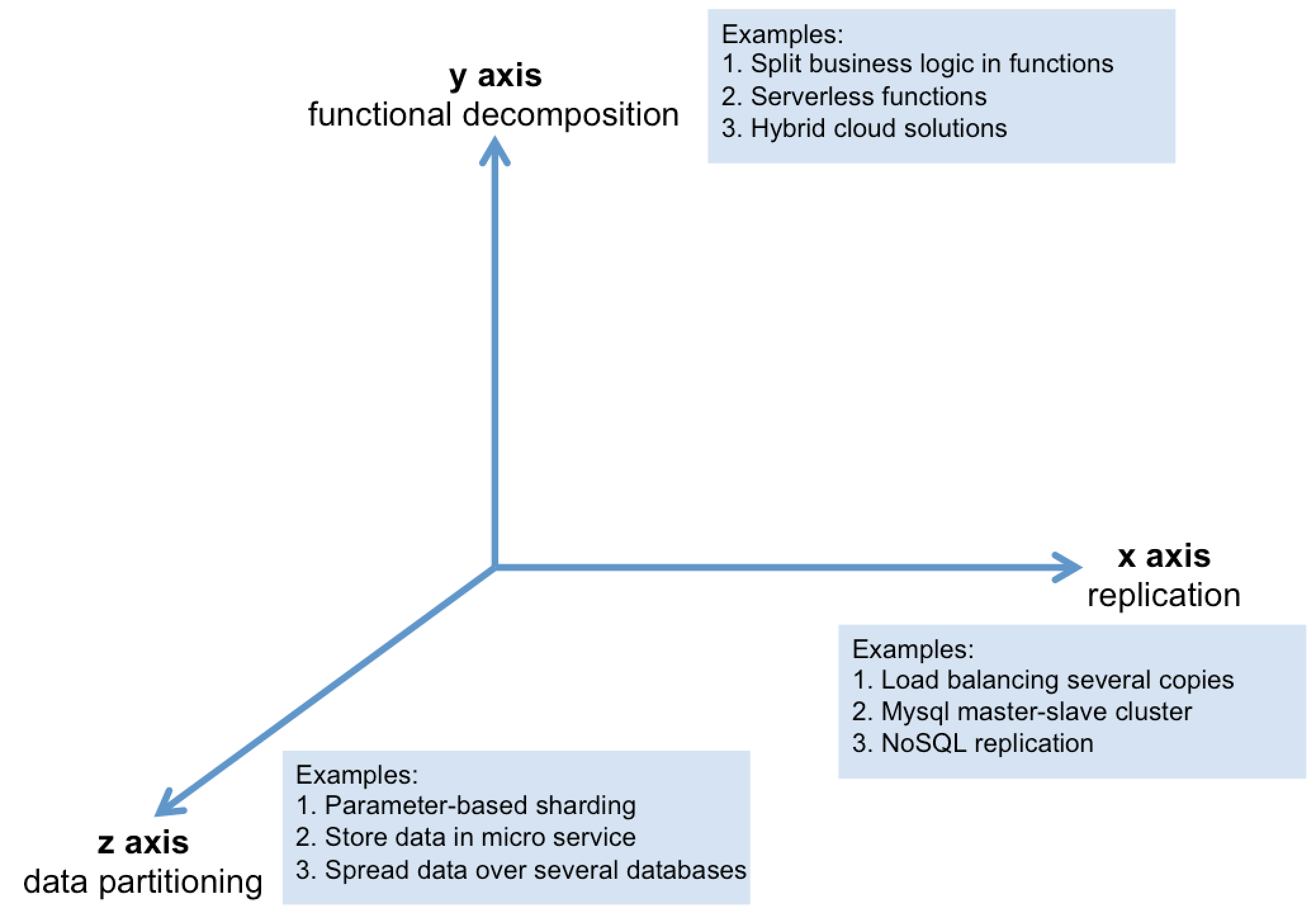
Observing the axis of the scale cube in the above figure (taken from the book “The Art of Scalability”), you will quickly note that micro services can be mapped to the cube’s y-axis, that is, functional decomposition. The x-axis contains all mechanisms for horizontal duplication or replication. Running multiple identical instances of one application behind a load balancer, for example, can be assigned to this class. Setting up a Mysql-master-slave cluster and replicating the slave nodes also qualifies. All mechanisms for data partitioning, however, correspond to the z-axis of the cube. This could be a method, for example, where an attribute of the request is used to determine the corresponding server of execution – what I call “parameter-based sharding.” For ConnectedVAN, for example, we could connect two brands to our fleet management solution: Audi and Volkswagen. In order to achieve this kind of parameter-based sharding all Volkswagen cars, for instance, could be routed to Volkswagen’s data centers, whereas Audi cars are directed to the Audi data centers. Thereby, we could distribute the load.
A good application usually makes use of all three types of scaling. Y-axis scaling, that is the functional decomposition, splits an application into micro services as described in the above figure. The Online Log Book, for example, could be scaled up by utilizing x-axis scaling. Several instances of the Online Log Book run in their own Docker container. This enables high availability. A load balancer upfront can be used to distribute the requests across all instances. Furthermore, the load balancer could be used for performance tuning by caching requests or for orchestration tasks such as access control, API metering or monitoring.
To leverage the full potential of the micro service architecture pattern, all micro services should have their own database. This database must suit the needs of the corresponding micro services. The Online Log Book, for example, uses a Cassandra database to allow for quick and flexible filtering of all data. The trip management is based on a Mongo database, since replication is an important requirement as well as the support of geo-queries. The user management uses a traditional relational Mysql database, since consistency and transactions are the most important requirements for this micro service.
Finally, I’ll discuss what is meant by the developer image – the small elephant. When developers start with the refactoring of their application, they may begin splitting the application into pieces and define interfaces. This is when you cut your elephant into pieces, i.e., exactly what you should avoid. At a huge company like Volkswagen, these pieces (typically the backend or frontend of a web application) are tied to suppliers. The suppliers must cooperatively define the interfaces allowing pieces to communicate. Defining such interfaces is where you lose most time. It’s far better to completely avoid splitting your application into such technical pieces. You should rather split it into customer-centric services. Such a service is the “online log book.” Since such a service uses all kinds of technical components (like the frontend user interface or the backend access to user data) you need a fully integrated developer image in order to allow such service teams to implement a new function over the entire stack. Your goal should always be to deliver a small elephant. How you implement and deliver such a developer image to your engineers depends on you. We did this, for example, by using the technology Docker Compose, a tool for defining and running multi-container Docker applications locally. This was quite practical since we wanted to use Docker as our core component for wrapping the micro services.
So, finally, we can conclude that a micro service architecture looks similar to an SOA architecture. With both approaches, the architecture encompasses of a set of services. The core difference between SOA and micro services, however, lies in the size and scope. As the word "micro" suggests, it has to be significantly smaller than what SOA tends towards. A micro service is a small(er) independently deployable unit. A SOA can be either a monolith or it can be comprised of multiple micro services. Martin Fowler (a very famous expert on agile software development methodologies) says he likes to think of SOA as superset of micro services.
Pain points
Despite their numerous advantages, micro services do come with a cost. One drawback is the subjective interpretation of the term micro service itself. The word “micro” calls for the development of small services. But how many lines of code is small? Indeed, there are developers who try to build extremely fine-grained services that consist of less than 100 lines of code. While small services are preferable, it’s important to keep in mind that small services are just the means to solve a problem, and not the primary goal itself. The split of the application into several services is done to facilitate agile development and deployment, not to figure out the smallest possible size of your puzzle parts. If you focus too much on decomposition, you may end up with a new and complex optimization problem: the well-known NP-complete subset sum problem. This would delay the process of delivering new services to your customer.
The next drawback of micro services is the complexity which attends distributed systems. If you need inter-process communication, you need to be able to cope with partial failure or unavailability of services. In addition to this, your micro services have their own databases. This means that you have more or less a partitioned databases. Business transactions, which have to update multiple business entities which are spread over several micro services, can be a challenge. This is easy to handle in monolithic, centralized applications but in distributed systems, you may end up with inconsistencies in your data. Your developers will have to implement best practices to avoid such inconsistencies, for example, based on queues to accept eventual consistency. Eventual consistency is often better than occasional inconsistency, so you may create a more robust solution using asynchronous communication. If you want to implement, for example, a user registration where each user also needs to have a billing account but both creations are split over two services, you can do the following. When a new user registers, you could add a message to a NewUser queue, and right-away reply to the user saying "You'll receive an email to confirm the account creation." A queue consumer service could process the message, perform the database changes in a single transaction, create the billing account, and send the email to the user to notify him about the complete account creation.
The next challenge is testing. All modern frameworks, such as Sprint Boot or Rails, have built-in mechanisms for testing monolithic applications. For testing a set of micro services, you have to abstract inter-process communication or spin up the entire system every time you run a test. Now if you implement a user story, which needs modifications of more than one service, you have to test all services together as well as deploy them in the correct order. In a monolithic application you could do your modifications, test them and deploy in one go. Fortunately, these complex changes do not occur very often.
Deploying a micro service based application is also much more challenging than deploying a monolithic application. In the context of a monolithic application, you usually modify the configuration settings for the production setup and start this single service behind a load balancer. In contrast, a micro service application may consist of hundreds or even, as in the case of Netflix, thousands of services. You will have to configure, deploy and scale every service on its own. Additionally, to keep from going insane, you will need to implement a service discovery mechanism that allows a service to discover the other services that it needs to communicate with. You will only be able to master this deployment monster with the highest level of automation. That’s exactly the reason why there are sophisticated Platform as a Service (PaaS) services - such as Cloud Foundry - out there which ease the deployment and management of micro services. PaaS can also be configured to guarantee best practices in compliance with company policies, which is usually important for large organizations.
So, my personal advice is to set up a developer image for your micro service architecture which is very similar to your production deployment. This means, for example, if you use Docker containers in production, you should set up your developer image with Docker. Thereby, you can do all the testing, for instance integration tests, during development and minimize the difference in the runtime environment. You should also have a look at Container as a Service (CaaS) solutions such as sloppy.io for your production environment. They have several tools which make the deployment, monitoring and scaling of containers much easier.
Why it is worth the pain
Using the micro service architecture pattern yields several important advantages. First, it helps reduce the complexity problem that you have to tackle in order not to lose innovation speed. Nevertheless, the complexity regarding deployment and integration increases but there are tools to handle this. Micro services help you tackle the complexity by decomposing your software into manageable modules. If you fail to do this, your monolithic application might grow into a monster. Additionally, the micro service pattern forces you to modularize your software from the very beginning. Thereby, you are able to develop new services faster. In the long term, this makes you faster and more agile.
Next, micro services enable you to parallelize your development. You can set up different teams which start working on different services in parallel. This is the next key to increasing your innovation speed dramatically. Since the developers are free to choose whatever technologies are suitable for the service they have to develop, they are free to choose the tools that ease development and additionally increase innovation speed. You will also be able to choose the newest technologies and recruit the most-skilled people in these fields. Furthermore, since each service is quite small, it gets more feasible to refactor code and rewrite old services based on modern technologies.
Third, a micro service architecture will enable you to deploy services independently. Changes limited to the one team’s service can be implemented without affecting other teams. Thereby, each individual team enjoys maximum autonomy, and can innovate and deploy at maximum speed. A UI team which optimizes the UI interface, for example, can do this independently from the backend teams. Micro services pave the way for continuous deployment.
Next, micro services enable the independent scaling of services. According to the needs of the service, you can ramp up instances, which satisfy the service’s requirements in terms of availability and capacity. Additionally, you can bring in the best-matching hardware for every service. A service, for example, processing massive amount of images in order to detect unwelcome human faces in food images (which happens from time to time if the pictures are provided from real users), can be deployed on EC2 Compute Optimized instances. A service using geo-information to calculate the nearest gas station, can be run on EC2 Memory-optimized instances, since in-memory databases are required for such a use case.
And last but not least, micro services will help you hack your organization. Since you’ll need to split your business logic into business services and staff cross-functional teams to work on them, you set the stage for for customer centricity in your organization. All the technical splits of the past won’t work any more. Agile software development techniques, moving applications to the cloud, DevOps culture, continuous integration and continuous deployment, and the use of containers will naturally reshape your company when you refactor an application into a micro service architecture.
Summary
Developing complex applications, such as ConnectedVAN or my own site Foodplaner.de, is a challenging task in terms of IT and software architecture. If you want to develop new features rapidly and not risk losing innovation speed due to the rapid growth of a monolithic-based application, you should refactor your application into a micro service architecture. The monolithic architecture pattern only makes sense to kickstart your application development at the beginning, when your application is still simple and lightweight.
In large organizations, micro services place the focus on customer centricity, an aspect that easily gets lost in big corporations. Agile software development techniques, moving applications to the cloud, DevOps culture, continuous integration and continuous deployment, and the use of containers will naturally reshape your company when you refactor an application into a micro service architecture.